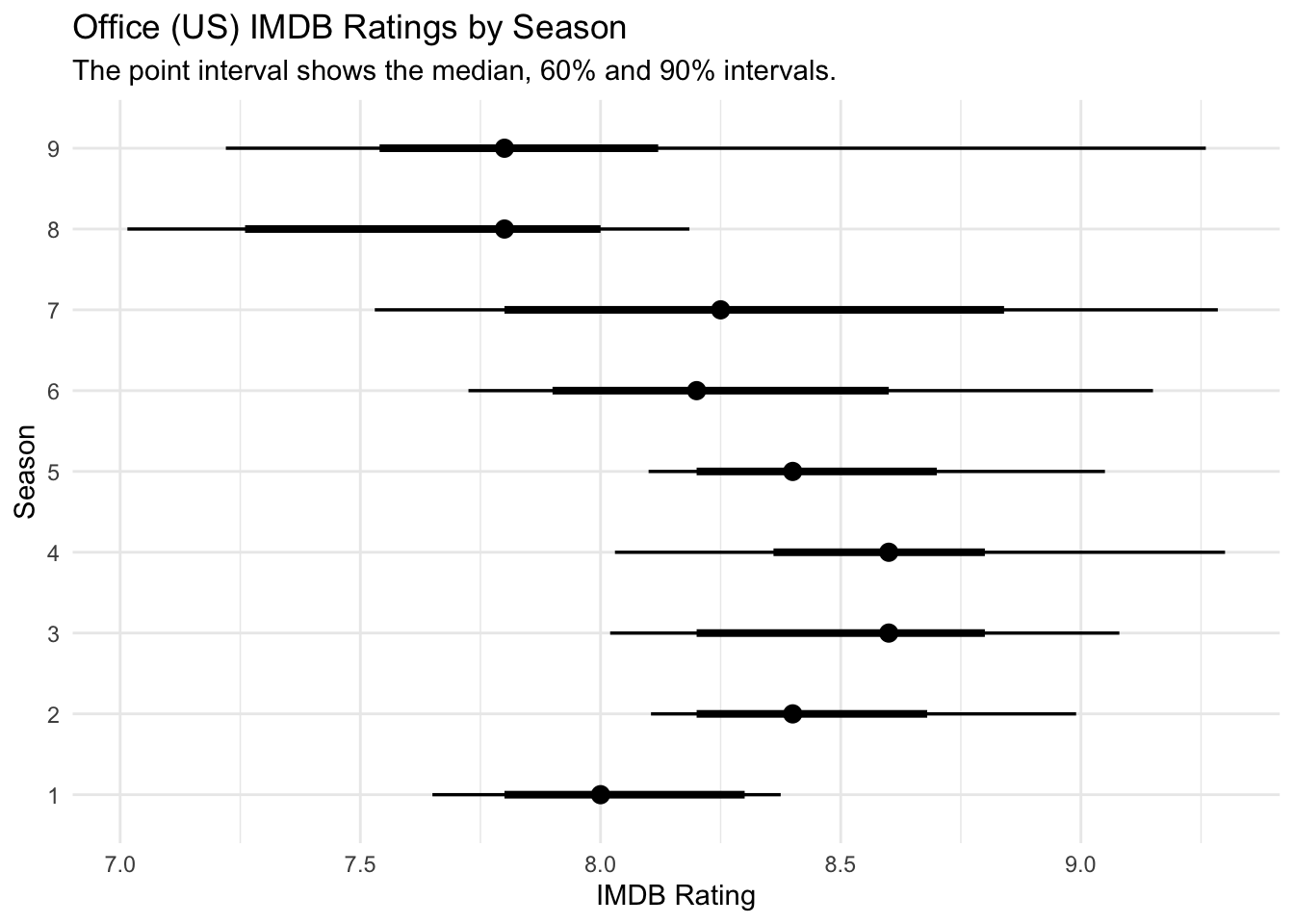
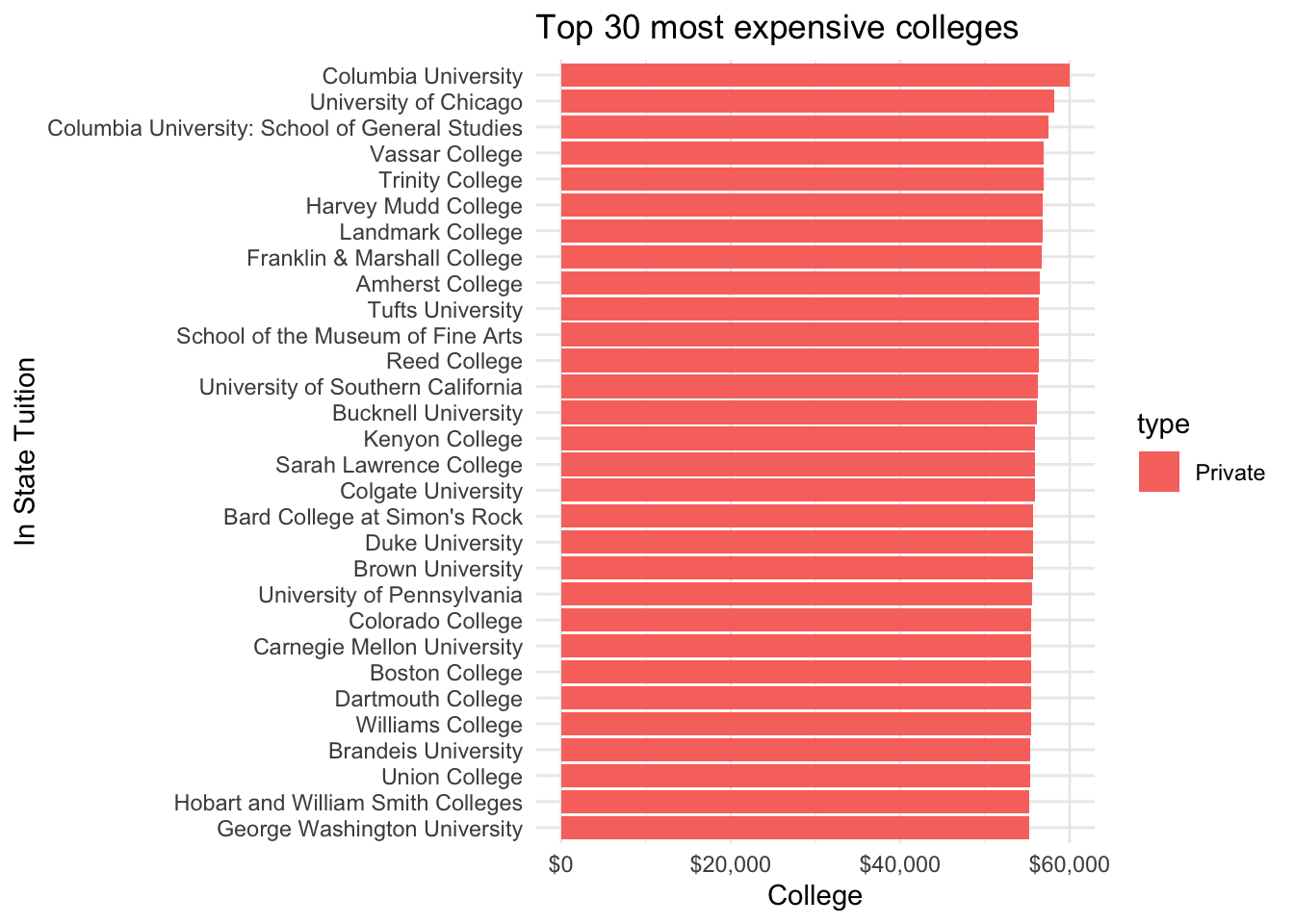
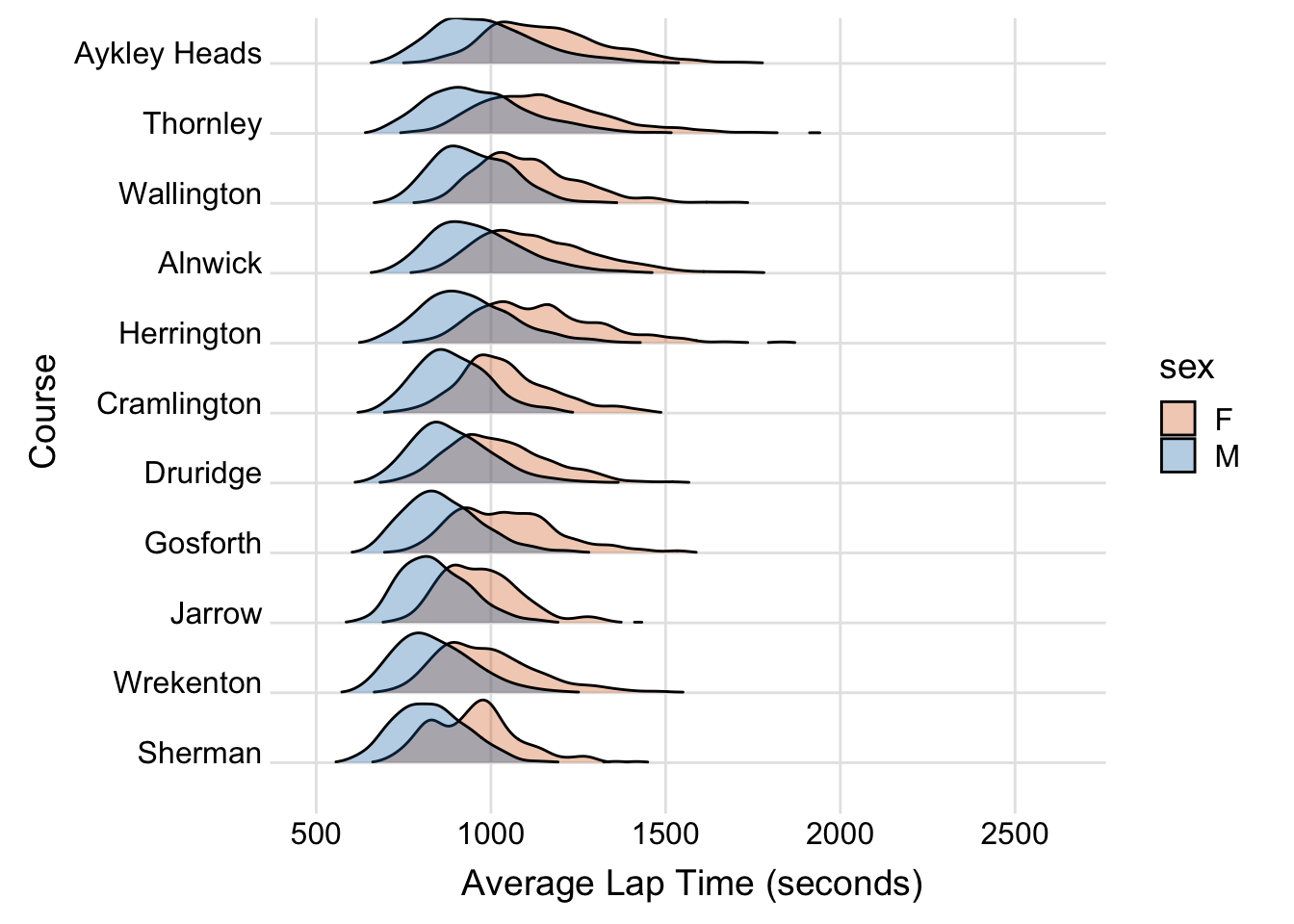
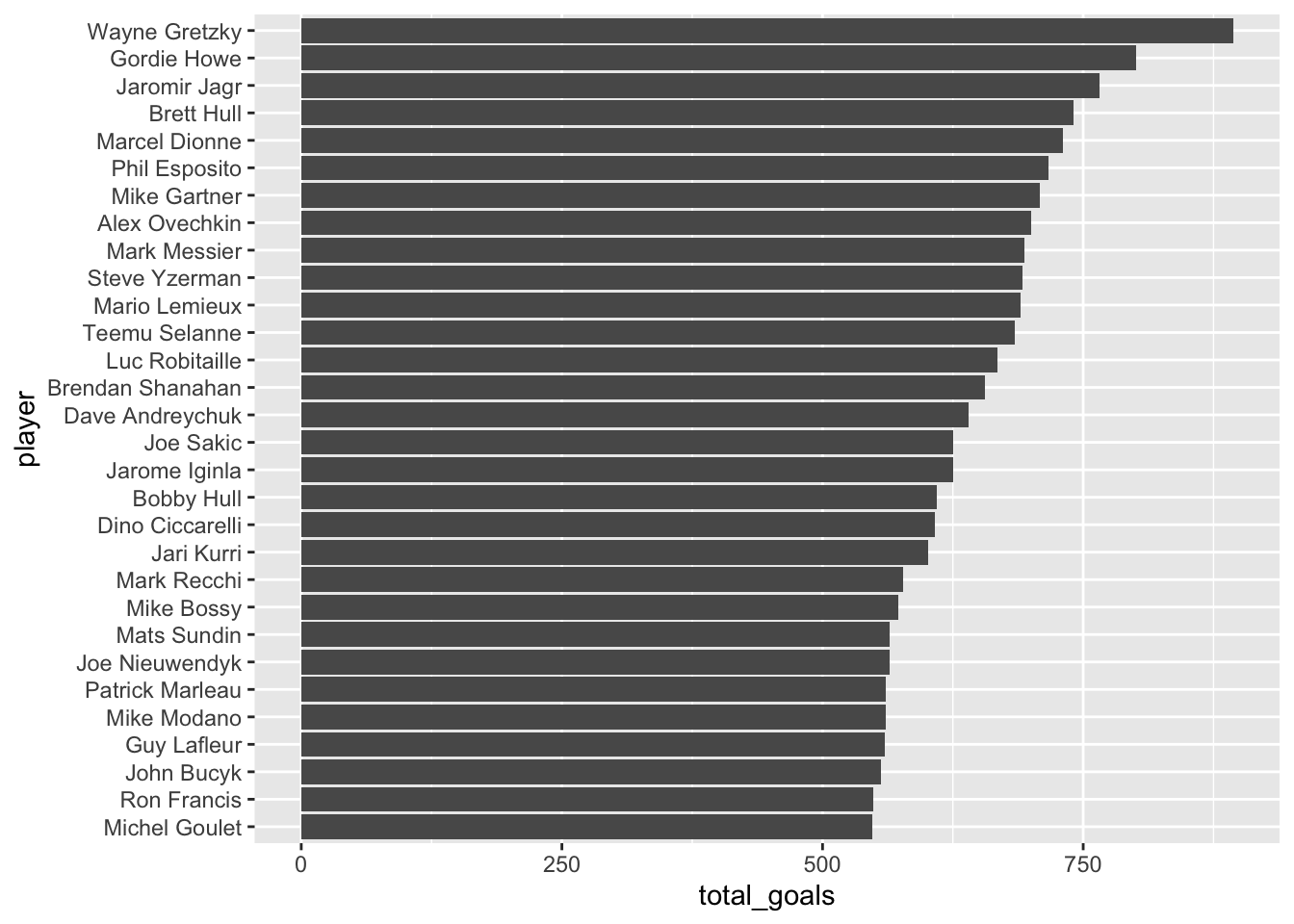
Introduction to managing cloud Infrastructure as Code (IaC) Collaboratively.
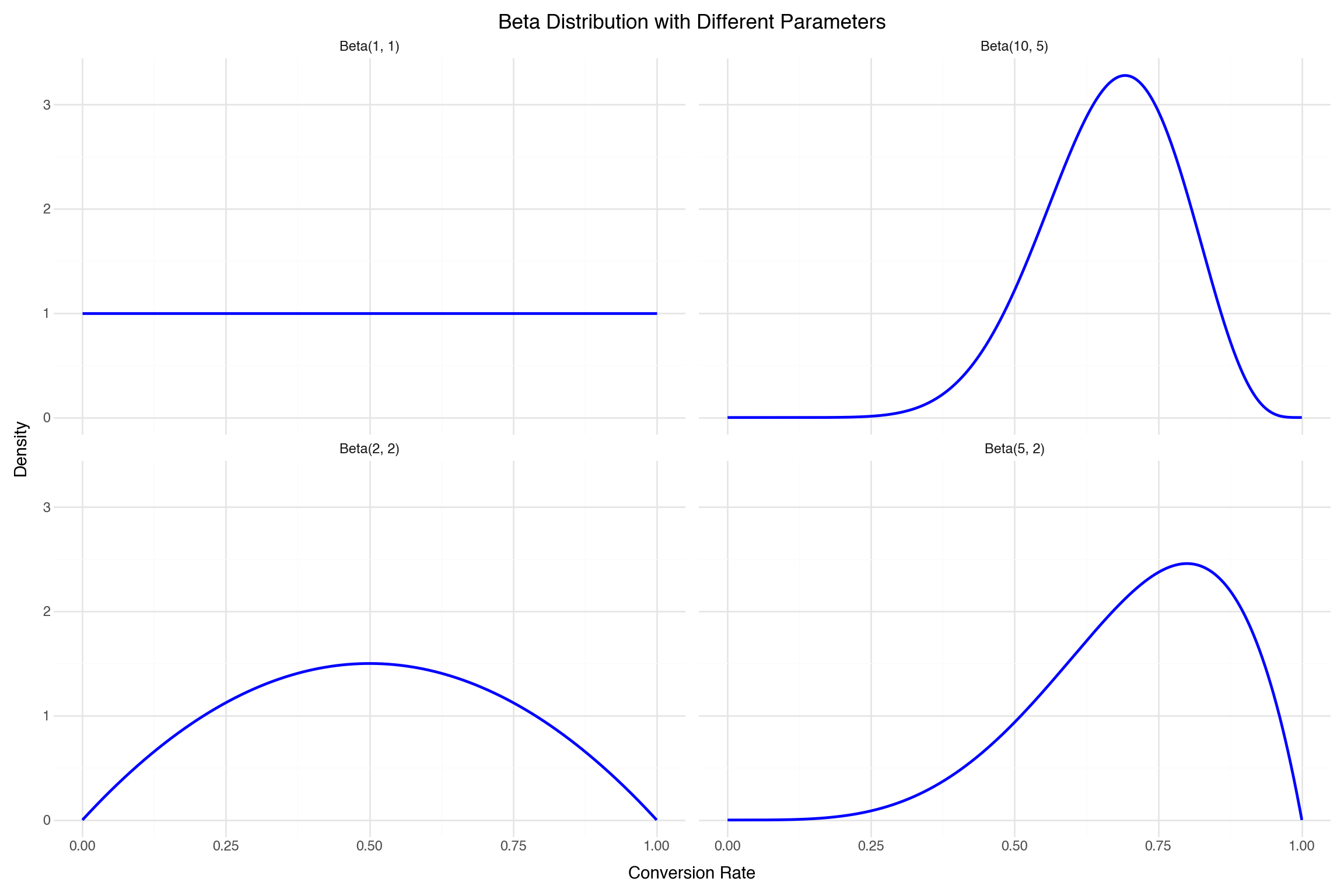
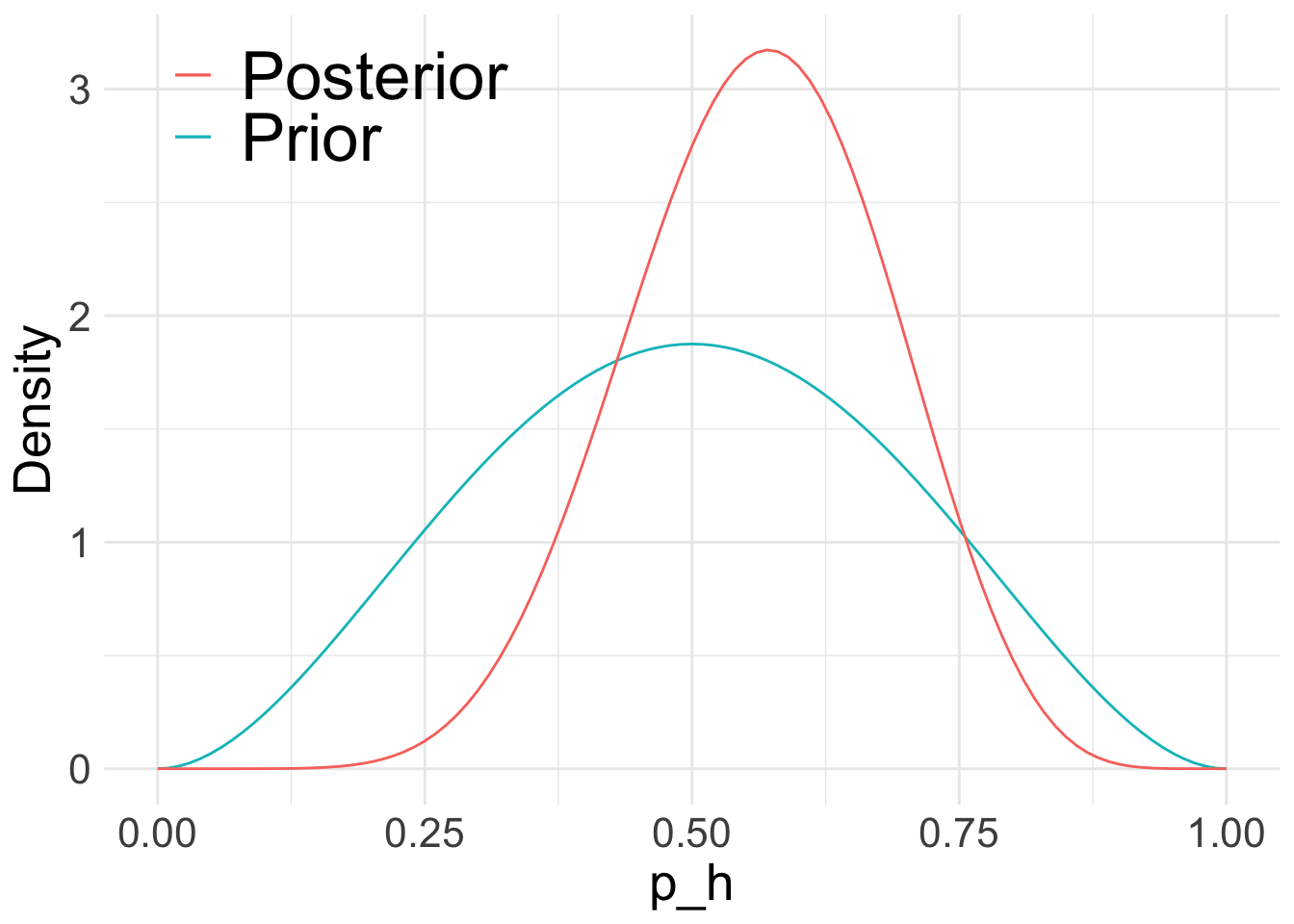
An introduction to Bayesian A/B testing using the conjugate beta-binomial model for conversion rate experiments.
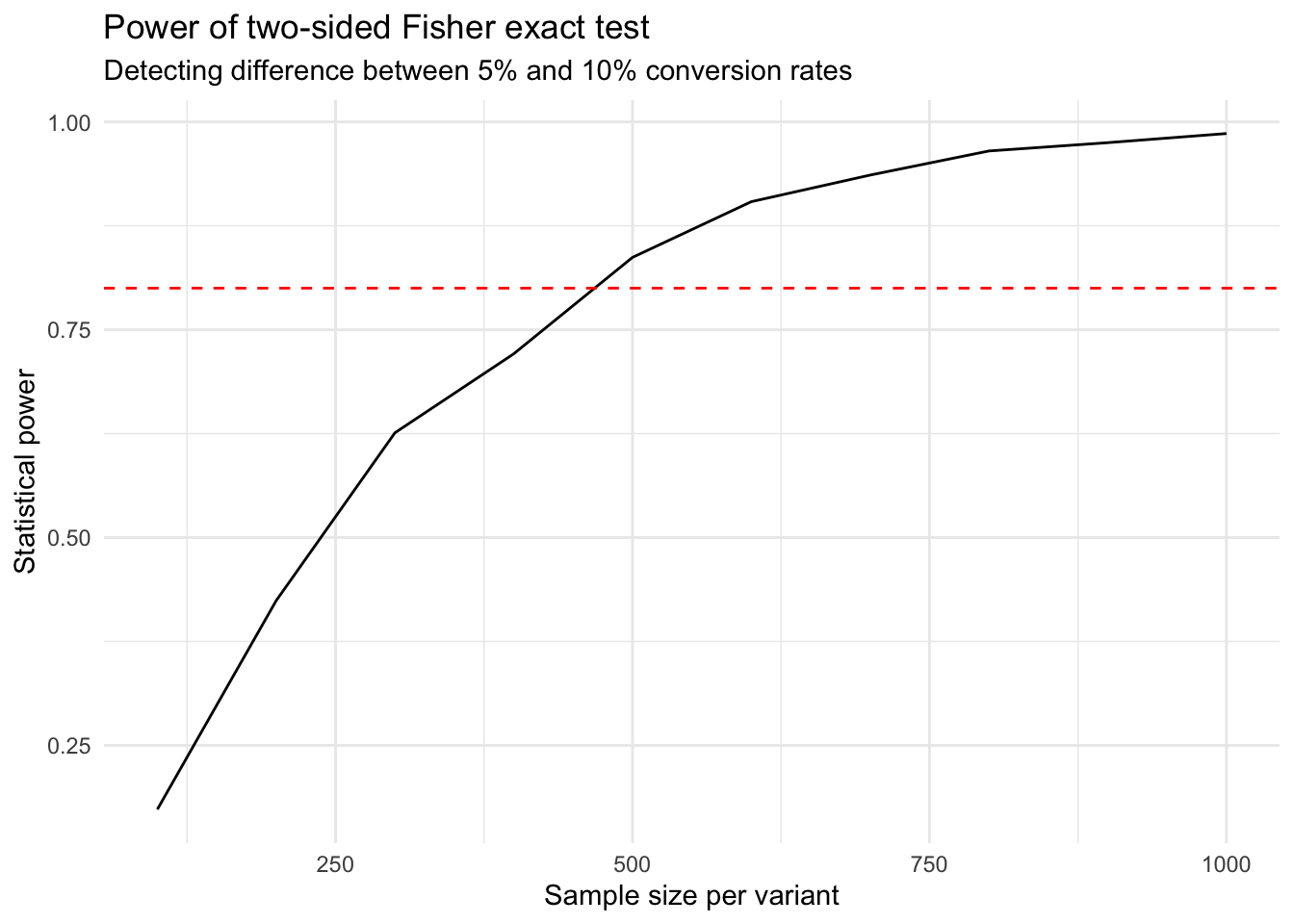
Using the Fisher exact test to analyse the results of an A/B test with a conversion metric outcome.
Comparing the performance of multiple machine learning models using Bayesian Hierarchical models.
Using MC Dropout to get probability intervals for neural network predictions.
Creating entity embeddings for categorical predictors using Python.
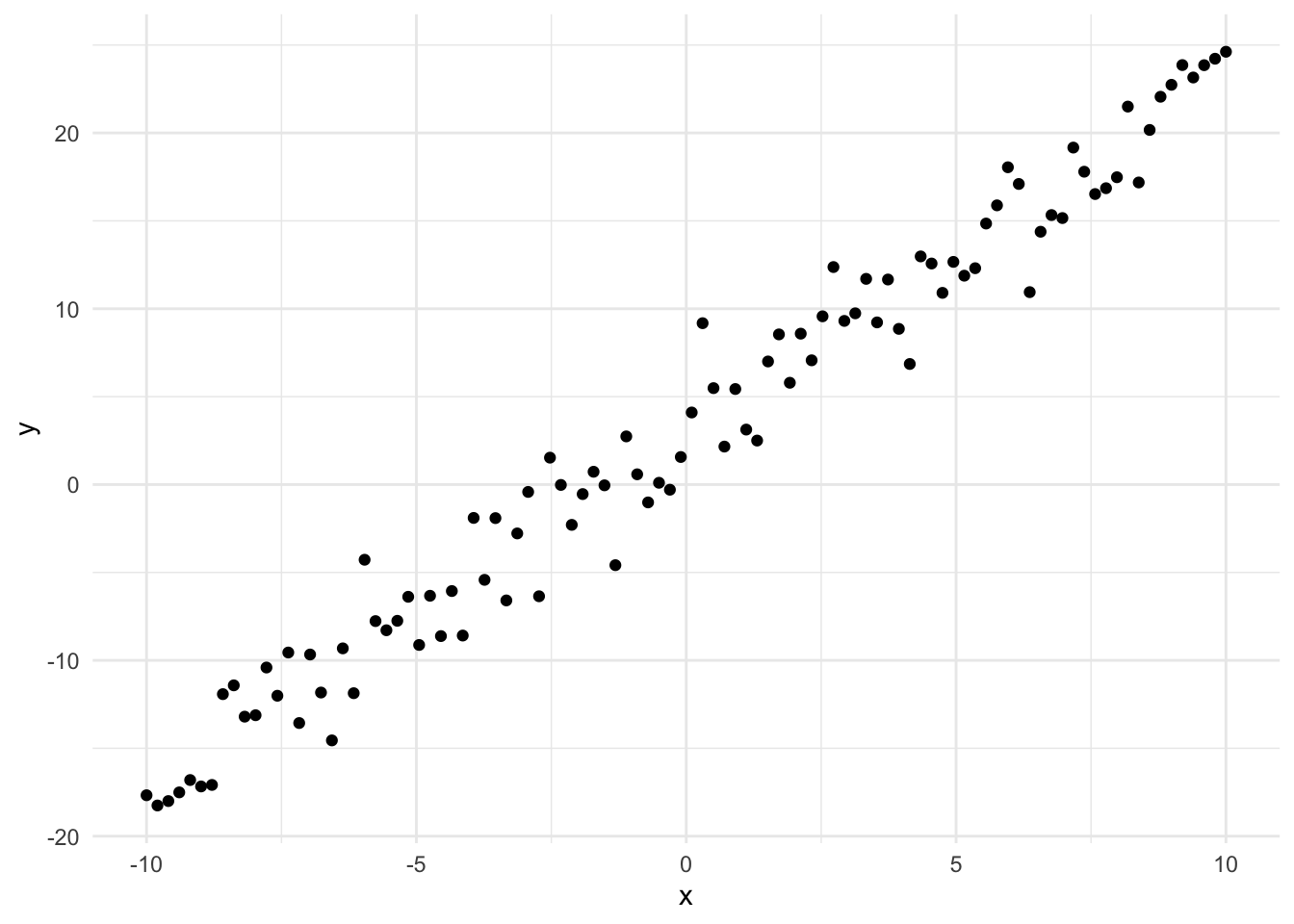
This post explores how to create a simple neural network to learn a linear function and a non-linear function using both standard R and the Torch library for R.